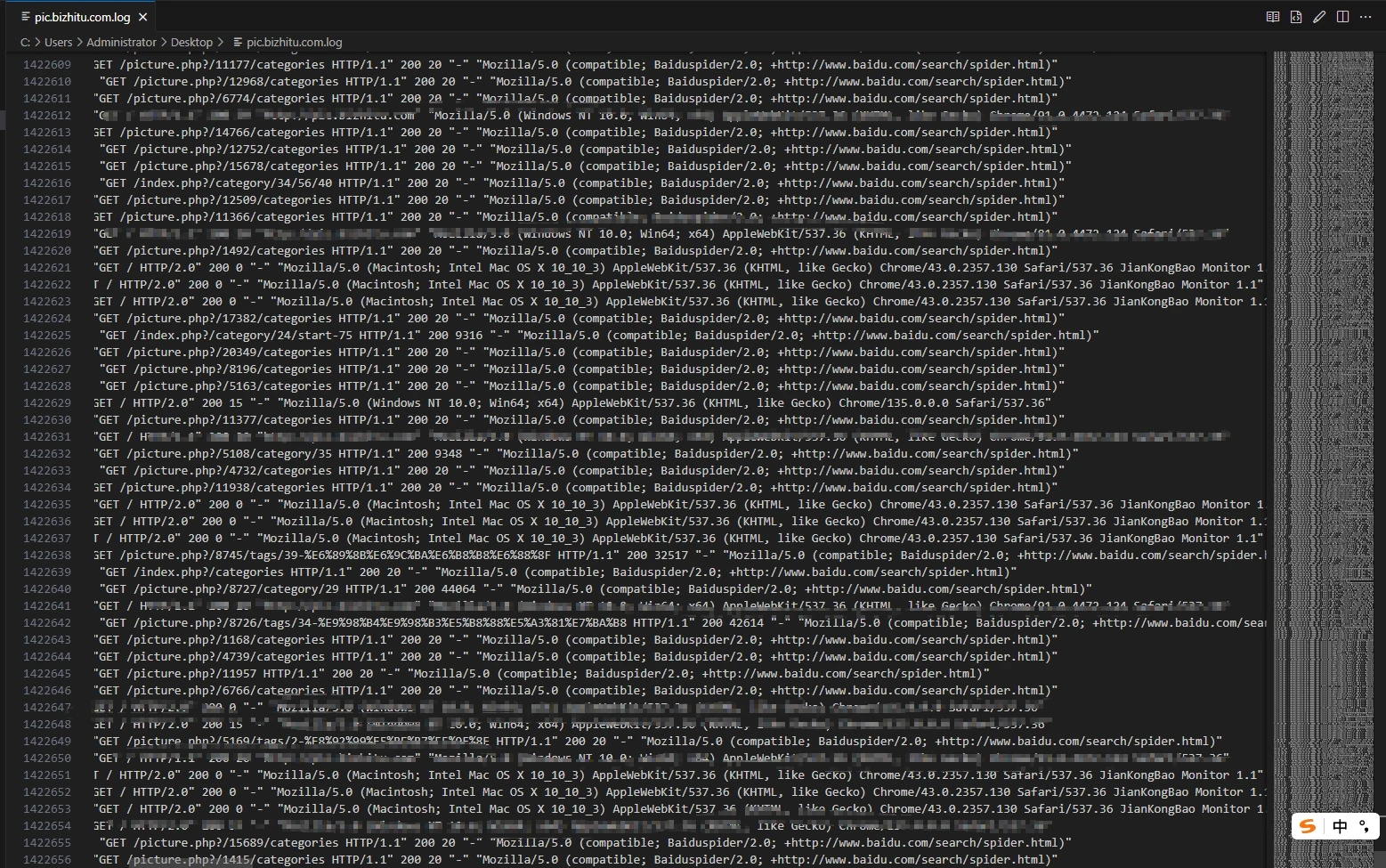
昨天中午开始,百度搜索引擎的爬虫就疯狂抓取网站内容,我都打不开网站,一直加载中然后就白屏了。
还以为要被收录了,然后到今天都打不开,没办法只能限制访问频率,分析日志发现了大量的AI爬虫记录,我一个破网站有啥好爬的,所以干脆都给禁了,下面记录下技术手段,有需要的可以参考。(不感兴趣的可以关闭页面)
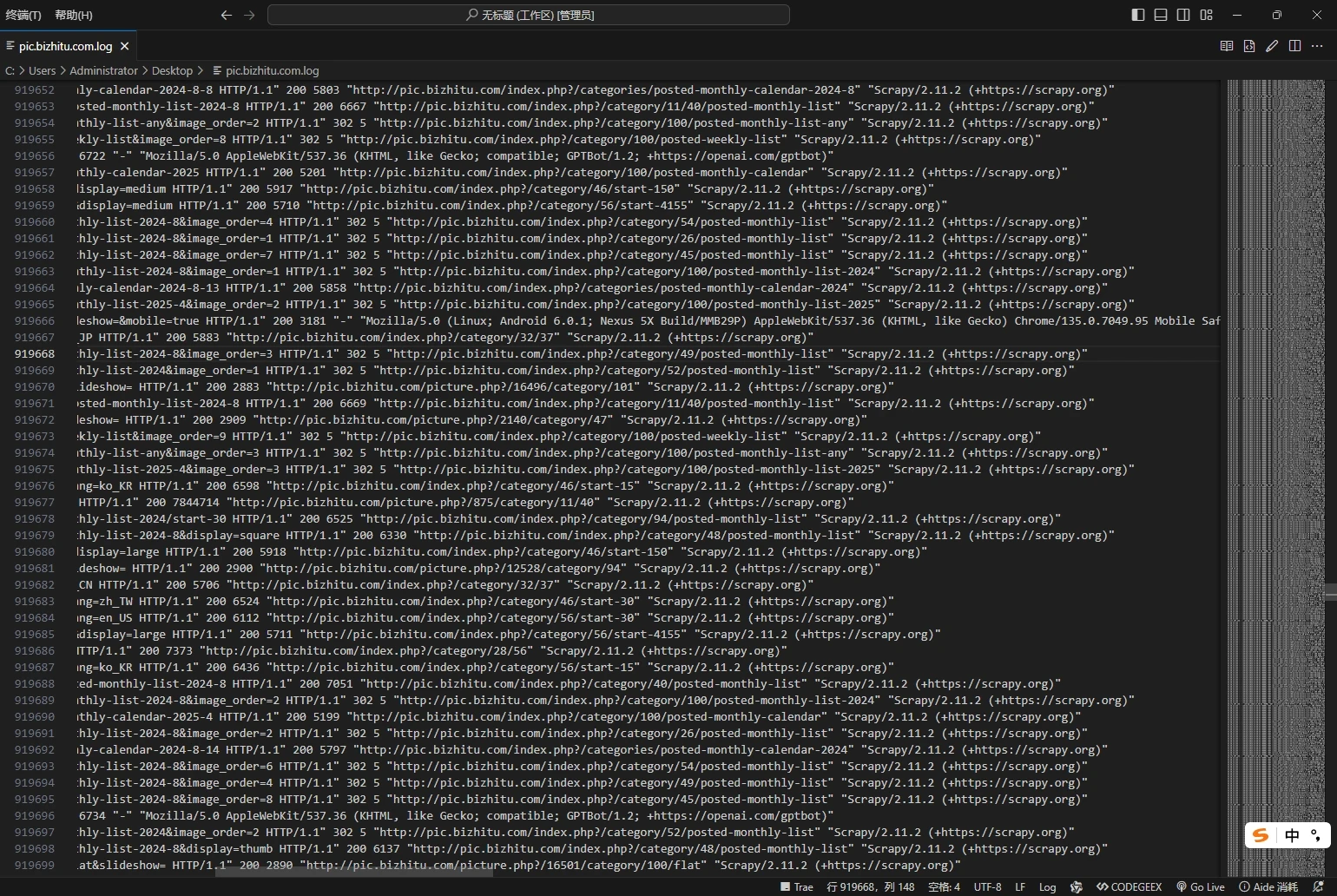
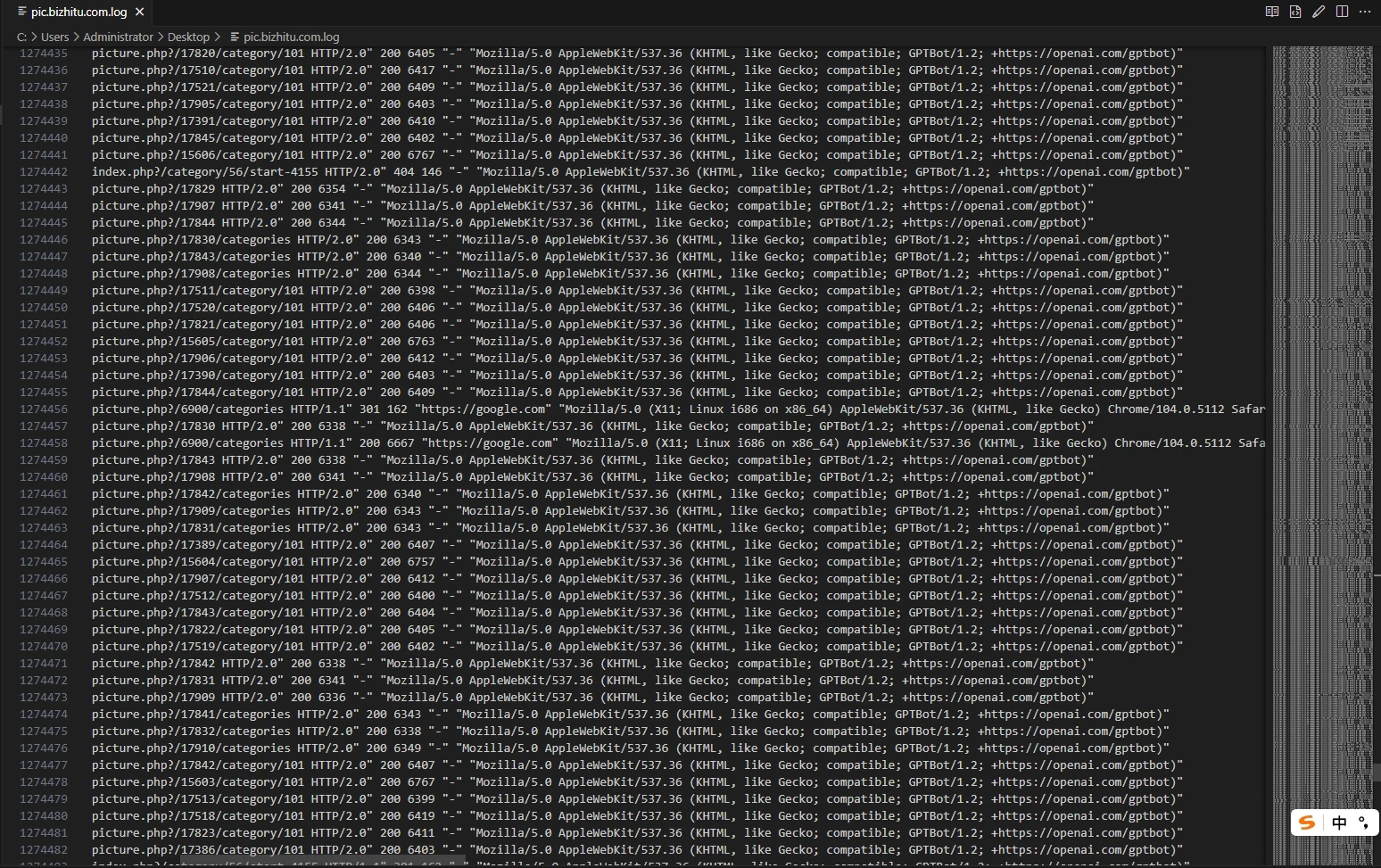
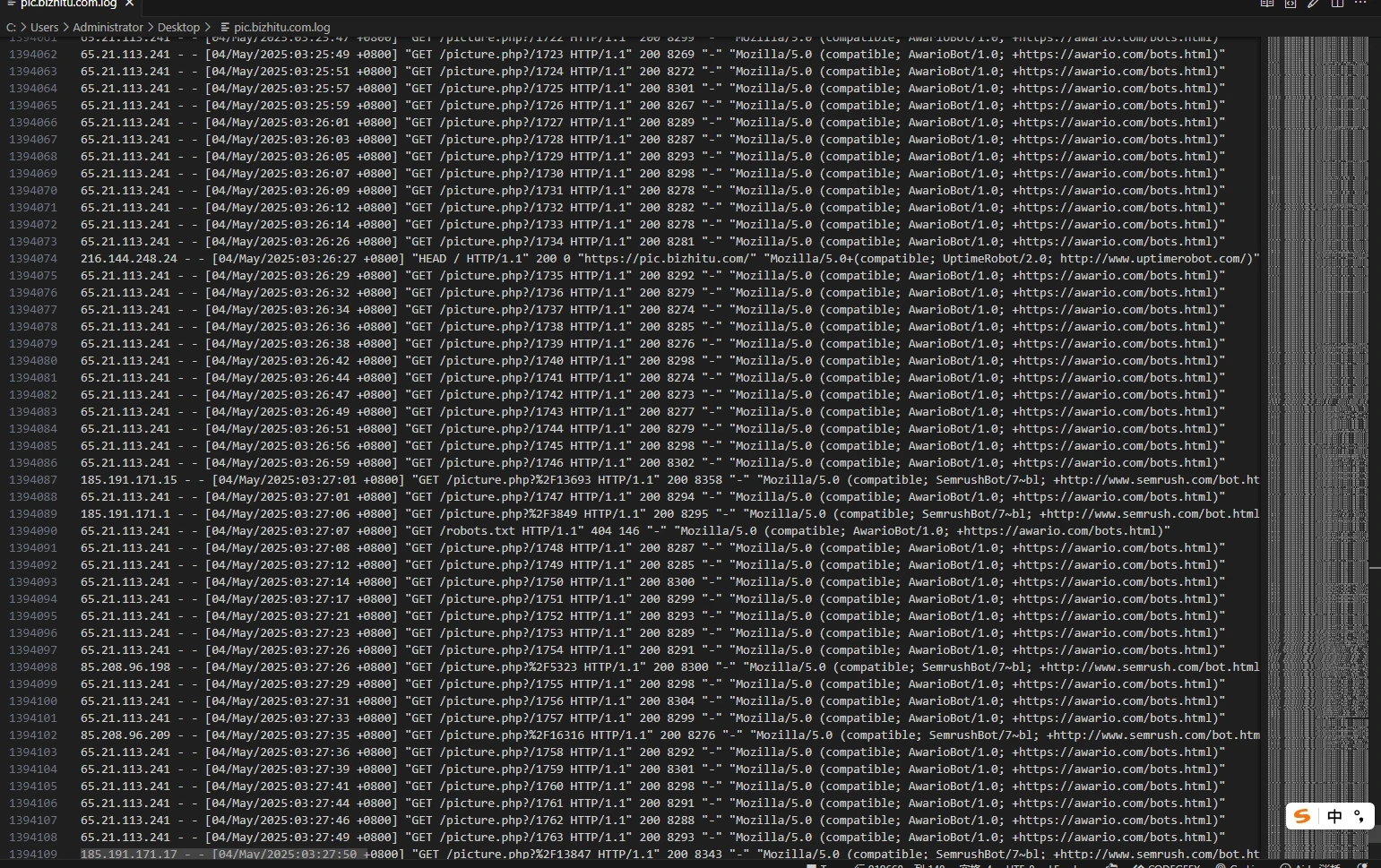
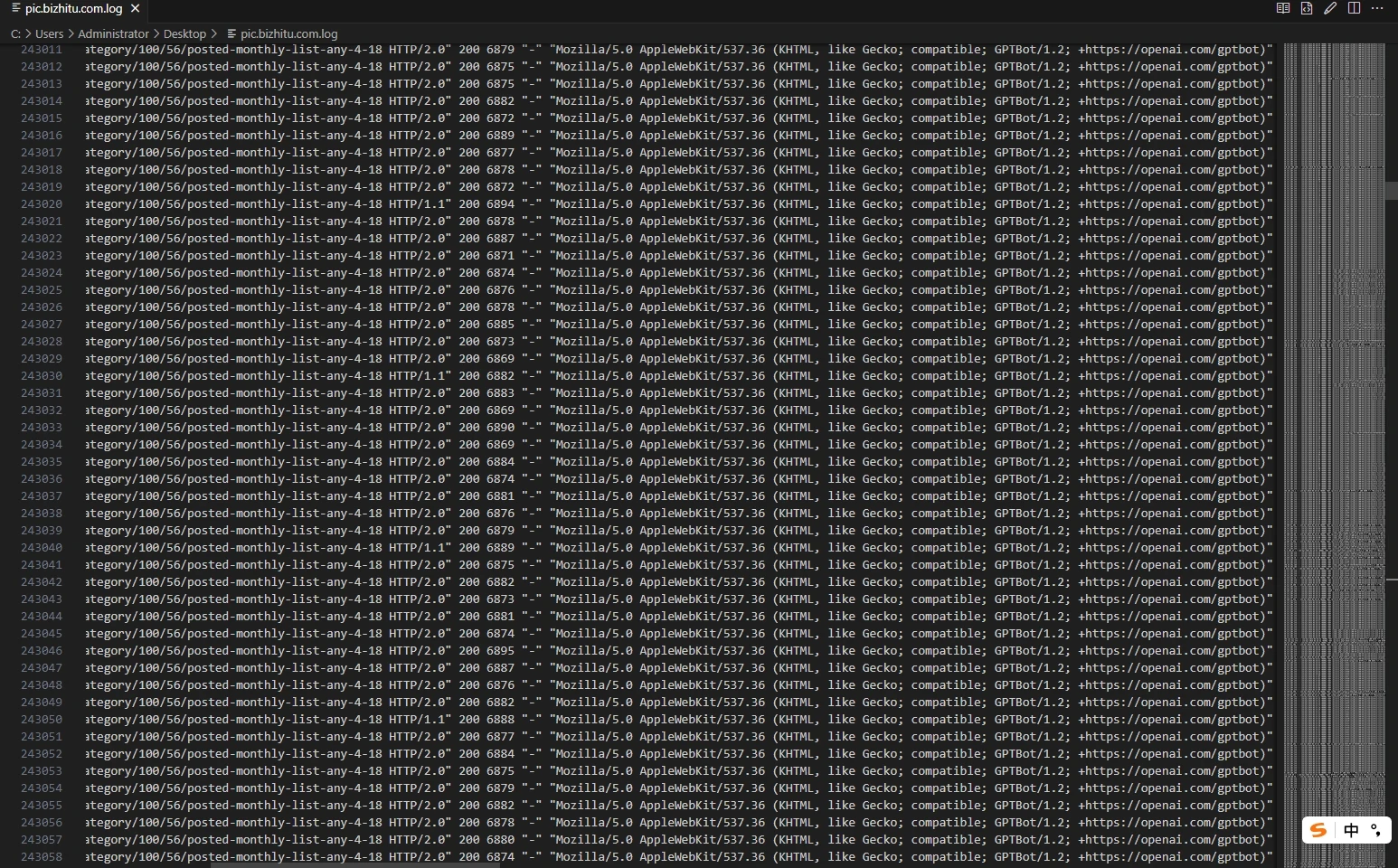
方案一
先是通过宝塔面板Nginx免费防火墙插件的User-Agent过滤了AI爬虫,参考资料:https://www.52txr.cn/2025/banaicurl.html
新增补充
(ScrapyIAwarioBotIAI2Bot|Ai2Bot-Dolma|aiHitBot|anthropic-ai|ChatGPT-User|Claude-Web|ClaudeBot|cohere-ai|cohere-training-data-crawler|Diffbot|DuckAssistBot|GPTBot|img2dataset|OAI-SearchBot|Perplexity-User|PerplexityBot|PetalBot|Scrapy|SemrushBot-OCOB|TikTokSpider|VelenPublicWebCrawler|YouBot)
又是用robots.txt限制AI爬虫和百度的爬取频率
# 百度蜘蛛:允许访问,但限制抓取间隔
User-Agent: Baiduspider
Crawl-delay: 5
# AI爬虫及特殊工具:禁止访问整个网站
User-Agent: Scrapy
Disallow: /
User-Agent: AwarioBotI
Disallow: /
User-agent: SemrushBot-BA
Disallow: /
User-agent: SemrushBot-SI
Disallow: /
User-agent: SemrushBot-SWA
Disallow: /
User-agent: SplitSignalBot
Disallow: /
User-agent: SemrushBot-OCOB
Disallow: /
User-agent: SemrushBot-FT
Disallow: /
User-Agent: AI2Bot
Disallow: /
User-Agent: Ai2Bot-Dolma
Disallow: /
User-Agent: aiHitBot
Disallow: /
User-Agent: Amazonbot
Disallow: /
User-Agent: anthropic-ai
Disallow: /
User-Agent: Applebot
Disallow: /
User-Agent: Applebot-Extended
Disallow: /
User-Agent: Brightbot 1.0
Disallow: /
User-Agent: Bytespider
Disallow: /
User-Agent: CCBot
Disallow: /
User-Agent: ChatGPT-User
Disallow: /
User-Agent: Claude-Web
Disallow: /
User-Agent: ClaudeBot
Disallow: /
User-Agent: cohere-ai
Disallow: /
User-Agent: cohere-training-data-crawler
Disallow: /
User-Agent: Cotoyogi
Disallow: /
User-Agent: Crawlspace
Disallow: /
User-Agent: Diffbot
Disallow: /
User-Agent: DuckAssistBot
Disallow: /
User-Agent: FacebookBot
Disallow: /
User-Agent: Factset_spyderbot
Disallow: /
User-Agent: FirecrawlAgent
Disallow: /
User-Agent: FriendlyCrawler
Disallow: /
User-Agent: Google-Extended
Disallow: /
User-Agent: GoogleOther
Disallow: /
User-Agent: GoogleOther-Image
Disallow: /
User-Agent: GoogleOther-Video
Disallow: /
User-Agent: GPTBot
Disallow: /
User-Agent: iaskspider/2.0
Disallow: /
User-Agent: ICC-Crawler
Disallow: /
User-Agent: ImagesiftBot
Disallow: /
User-Agent: img2dataset
Disallow: /
User-Agent: imgproxy
Disallow: /
User-Agent: ISSCyberRiskCrawler
Disallow: /
User-Agent: Kangaroo Bot
Disallow: /
User-Agent: Meta-ExternalAgent
Disallow: /
User-Agent: Meta-ExternalFetcher
Disallow: /
User-Agent: NovaAct
Disallow: /
User-Agent: OAI-SearchBot
Disallow: /
User-Agent: omgili
Disallow: /
User-Agent: omgilibot
Disallow: /
User-Agent: Operator
Disallow: /
User-Agent: PanguBot
Disallow: /
User-Agent: Perplexity-User
Disallow: /
User-Agent: PerplexityBot
Disallow: /
User-Agent: PetalBot
Disallow: /
User-Agent: Scrapy
Disallow: /
User-Agent: SemrushBot-OCOB
Disallow: /
User-Agent: SemrushBot-SWA
Disallow: /
User-Agent: Sidetrade indexer bot
Disallow: /
User-Agent: TikTokSpider
Disallow: /
User-Agent: Timpibot
Disallow: /
User-Agent: VelenPublicWebCrawler
Disallow: /
User-Agent: Webzio-Extended
Disallow: /
User-Agent: YouBot
Disallow: /
结果没有任何卵用...
方案二(一起使用)
豆包给的方案
全局的NGINX配置文件中添加(在http { 内添加)
# 1. 定义百度蜘蛛的User-Agent匹配规则(必须在http块内)
map $http_user_agent $is_baidu_spider {
default 0;
"~*Baiduspider" 1; # 匹配百度蜘蛛的 User-Agent
}
# 2. 定义限流区域(限制百度蜘蛛的请求频率)
limit_req_zone $binary_remote_addr$is_baidu_spider zone=baidu_spider:10m rate=100r/m;
# rate=300r/m:每个IP每分钟最多300次请求(可根据服务器性能调整)
然后到网站配置规则里添加(在server { 内添加)
# ------------------------ 缩略图专用优化(匹配完整路径) ------------------------
# 匹配 /_data/i/upload/ 目录下的所有图片文件(含时间子目录,如 /2024/08/08/)
location ~* ^/_data/i/upload/.*\.(jpg|jpeg|png|webp|avif|heic|heif)$ {
# 强缓存1年(CDN/浏览器均可缓存)
add_header Cache-Control "public, max-age=31536000";
# 兼容旧浏览器(30天缓存)
expires 30d;
# 关闭缩略图访问日志(减少磁盘IO)
access_log /dev/null;
# 继承全局防盗链规则(非法 Referer 已被拦截,无需重复判断)
}
# ------------------------ AI 爬虫与原图保护 ------------------------
# 定义需拦截的 User-Agent(AI 爬虫 + 恶意工具)
set $block_ua 0;
if ($http_user_agent ~* "(HTTrack|Apache-HttpClient|harvest|audit|dirbuster|pangolin|nmap|sqln|hydra|Parser|libwww|BBBike|sqlmap|w3af|owasp|Nikto|fimap|havij|zmeu|BabyKrokodil|netsparker|httperf|SF|AI2Bot|Ai2Bot-Dolma|aiHitBot|ChatGPT-User|ClaudeBot|cohere-ai|cohere-training-data-crawler|Diffbot|DuckAssistBot|GPTBot|img2dataset|OAI-SearchBot|Perplexity-User|PerplexityBot|Scrapy|TikTokSpider|VelenPublicWebCrawler)") {
set $block_ua 1;
}
# 放行合法搜索引擎(百度、谷歌等)
if ($http_user_agent ~* "(Baiduspider|Googlebot|bingbot|YandexBot|Sogou web spider|Bytespider)") {
set $block_ua 0;
}
# 针对原图目录(/upload/)强化拦截(仅拦截恶意 UA,不影响正常用户)
location ~* ^/upload/ {
if ($block_ua = 1) {
return 403;
}
try_files $uri $uri/ =404;
}
# ------------------------ 对动态页面限流(仅百度蜘蛛受影响) ------------------------
location ~* ^/(picture.php|index.php) {
# 直接应用限流(仅当 $is_baidu_spider=1 时,限流生效)
limit_req zone=baidu_spider burst=20 nodelay;
# 原有 PHP 处理逻辑(如 include enable-php-84.conf)
include enable-php-84.conf;
}
# ------------------------ 其他配置 ------------------------
缩略图什么的是我网站使用的,根据实际情况修改。
方案三
拉黑搜素引擎和AI蜘蛛的IP段(会导致网站内容不被收录)
网站缓过来了在解除试下
这家伙太懒了,什么也没留下。
给楼主投上 1 枚硬币
当前您的硬币余额:0




